10 Key Optimizations That Make LLM Inference Unique
Large language models (LLMs) have revolutionized AI, but serving them efficiently at scale is far more complex than traditional deep learning models like CNNs for image classification. In a viral street interview in San Francisco, Robert Nishihara (co-founder of Anyscale and creator of Ray) casually broke down 5 core reasons why LLM inference requires specialized engines like vLLM, SGLang, and TensorRT-LLM.
This blog expands his insights into 10 key optimizations, reordered chronologically along the inference pipeline from request arrival to token generation and scaling. Each includes deeper explanations, real-world implications, and visuals (recreated faithfully from the original video where applicable, plus standard diagrams from the field).
These techniques explain why off-the-shelf serving systems fall short and why dedicated LLM inference engines deliver 10-50x better throughput and latency.

1. Autoregressive Token-by-Token Generation
Traditional models (e.g., CNNs) process fixed inputs and produce fixed outputs in one pass. LLMs generate outputs autoregressively: one token at a time, feeding each new token back as input.
This creates sequential dependency no full parallelization across output length and makes computation variable (short chats vs. long essays).
Impact: Decode phase becomes bottleneck; enables open-ended generation but requires caching past computations.
Traditional Model (e.g., Classification)
Input → [Full Forward Pass] → Output (fixed)
LLM Autoregressive Generation
Prompt → Token1 → Token2 → ... → TokenN (sequential loop)
↑_____________________________↓ (feedback)
2. Variable-Length Inputs and Outputs
Unlike fixed-size images (e.g., 224x224), LLM prompts and responses vary wildly in length.
This irregularity complicates batching and memory allocation, traditional static batching wastes resources on padding.
Impact: Dynamic scheduling needed; engines must handle uneven workloads without dropping efficiency.
Video Visual Recreation (ASCII):
Fixed (CNN) Variable (LLM)
+----------------+ +----------------+
| Fixed Input | → Model → | Fixed Output |
+----------------+ +----------------+
+----------------+ +----------------+
| Input: ???? | → Model → | Output: ????? |
+----------------+ +----------------+
3. Distinct Prefill and Decode Phases
LLM inference splits into two phases:
- Prefill: Parallel processing of entire prompt (compute-intensive, matrix-heavy).
- Decode: Sequential token generation (memory-bandwidth-bound, small computations per step).
They have opposing resource needs, running them together causes interference and unpredictable latency.
Impact: Optimal scheduling separates them for stability.
Video Visual Recreation (ASCII):
Input → [Prefill: Compute-Heavy] │ [Decode: Memory-Heavy] → Output
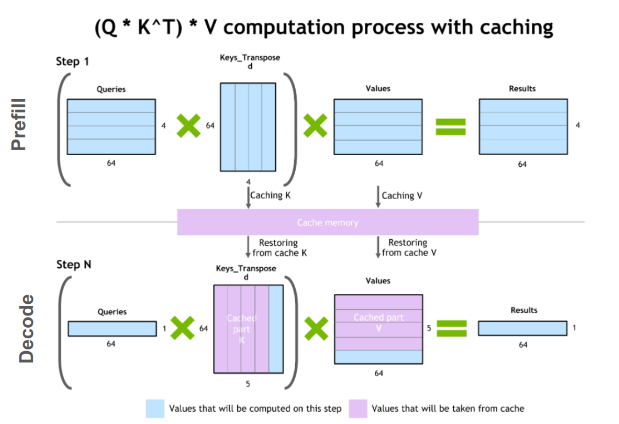
4. Key-Value (KV) Caching
During attention, keys and values for past tokens are cached to avoid recomputation.
In multi-turn chats or long contexts, shared prefixes mean massive redundant work without caching.
Impact: Reduces compute from O(n²) to O(n) per new token; but KV cache grows linearly, dominating GPU memory.
Video Visual Recreation (ASCII):
Turn 1: [Prefix ...] → Response1 (compute KV)
Turn 2: [Prefix ...] → Response2 (reuse KV → only new tokens)
↑↑↑↑↑↑↑↑
KV Cache

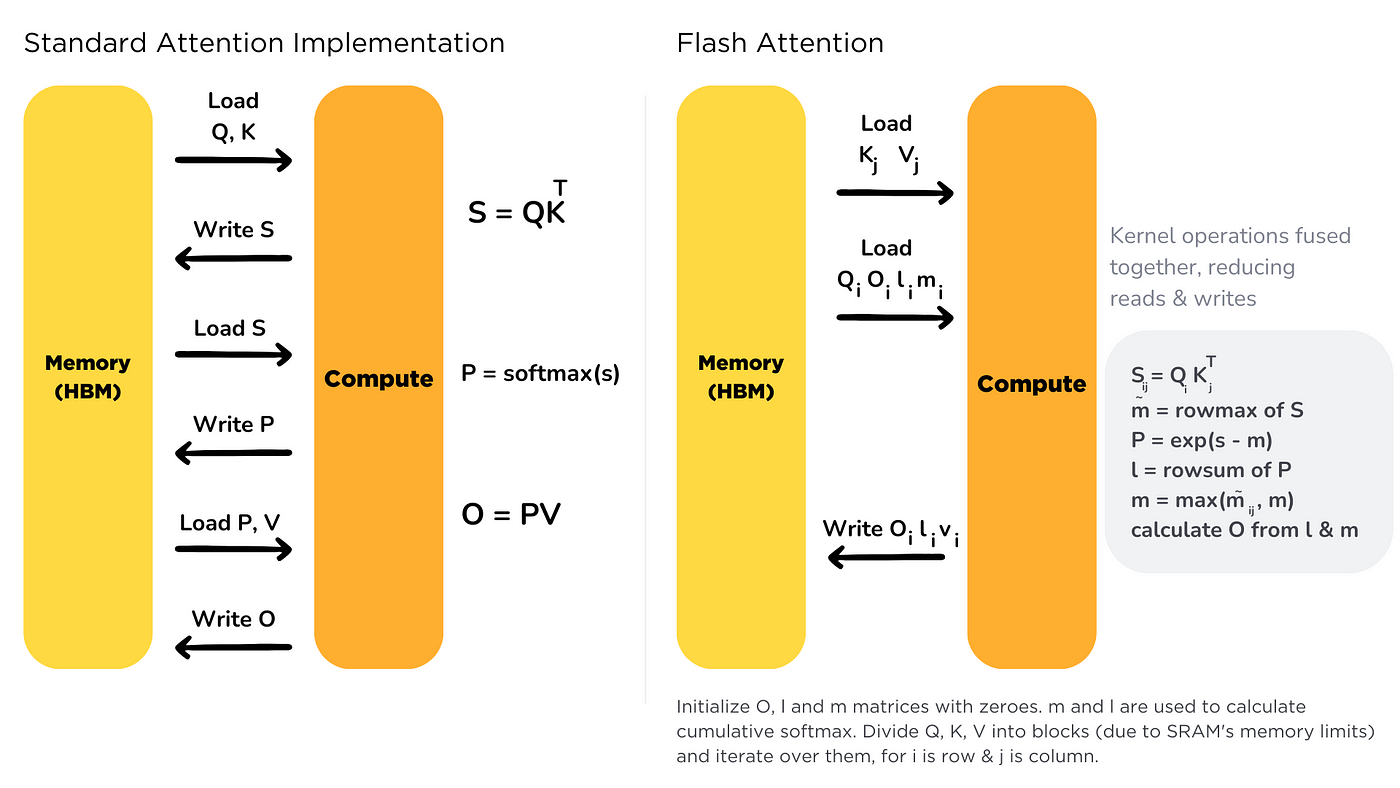
5. Optimized Attention Kernels (e.g., FlashAttention)
Standard attention is memory-bound and quadratic. FlashAttention fuses operations, tiles data into SRAM, and avoids materializing full attention matrix.
Impact: 2-4x speedup on long sequences; essential for large contexts (e.g., 128k tokens).
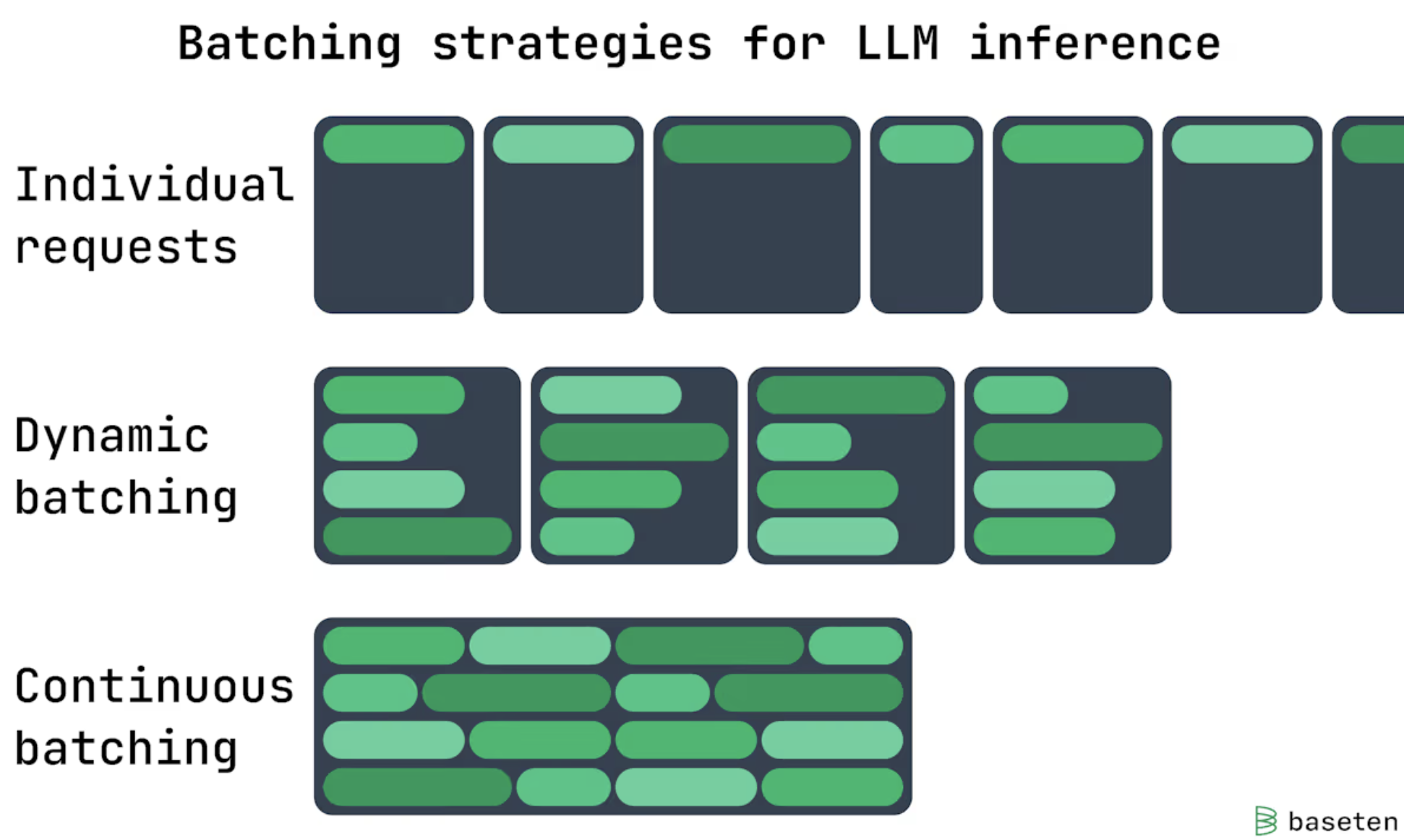
6. Continuous (In-Flight) Batching
Static batching waits for full batches and struggles with variable lengths (early finishes waste slots).
Continuous batching dynamically swaps completed sequences with new ones mid-flight.
Impact: Keeps GPUs saturated; up to 20-30x higher throughput under bursty traffic.
Video Visual Recreation (ASCII):
Time → t1 t2 t3 t4
Seq A: ██████ ██████ ██████ ██████ (long)
Seq B: ████ ████ (finishes → swap out)
Seq C: ████████ ████████ (swapped in)
7. PagedAttention for KV Cache Management
KV cache grows unpredictably and causes fragmentation in contiguous memory.
vLLM’s PagedAttention borrows OS virtual memory: stores KV in fixed-size pages/blocks, mapped via pageable tables.
Impact: Near-zero waste; enables higher batch sizes and longer contexts without OOM.
Video Reference: Inspired by virtual memory (vLLM paper shown on-screen).
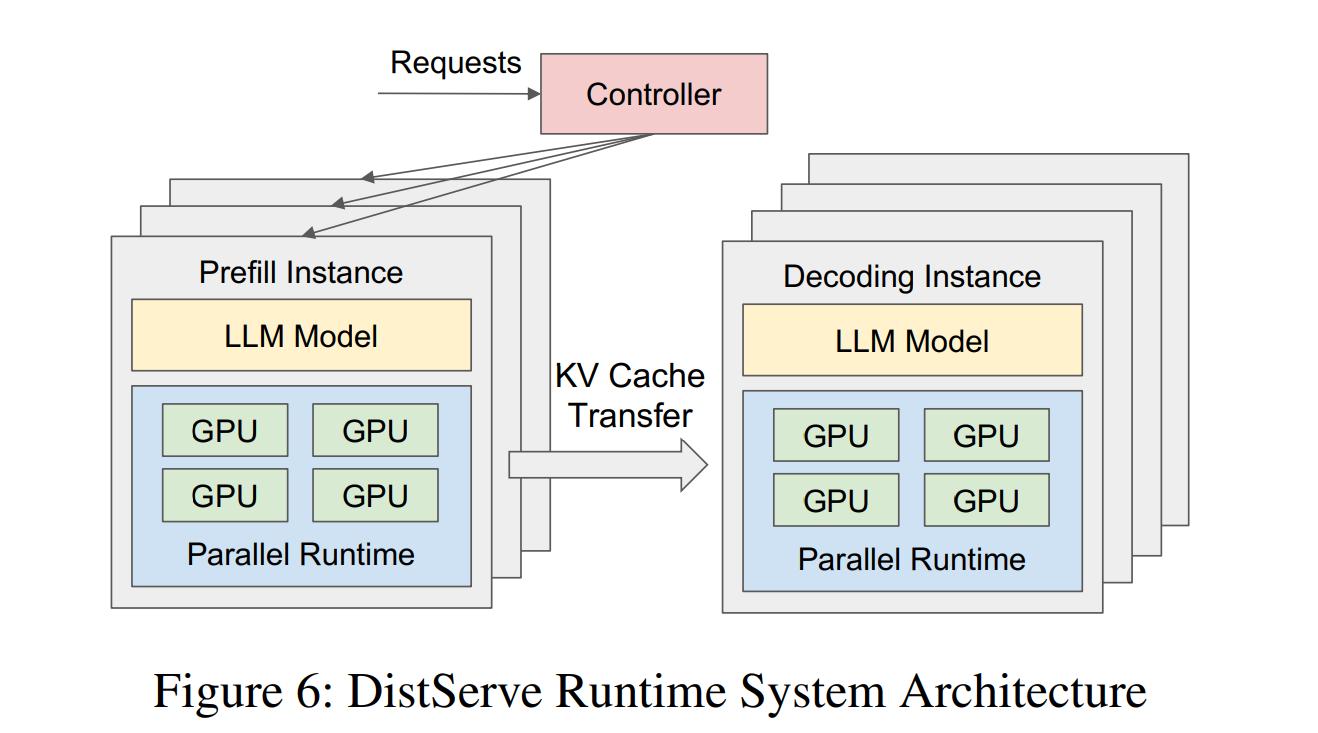
8. Prefill-Decode Disaggregation
Since prefill (compute-bound) and decode (memory-bound) conflict, top systems run them on separate GPU pools and shuttle KV cache between.
Impact: Predictable latency, better utilization; critical for production SLOs.
Video Visual: Separate pools with data movement arrow.
9. Prefix-Aware (Cache-Aware) Routing
Traditional load balancing (round-robin) ignores cached prefixes.
With shared conversation history, route continuations to replicas holding relevant KV cache for hits.
Impact: Reduces recompute; boosts efficiency in chat/apps with multi-turn sessions.
Video Visual Recreation (ASCII):
Incoming Query (Prefix X)
↓
[Router]
↓
Replica A (KV: X) ← HIT!
Replica B (KV: Y)
Replica C (KV: Z)
10. Specialized Sharding for Mixture-of-Experts (MoE) Models
Top models (e.g., Mixtral, Grok) are MoE: attention layers replicated, expert layers sharded across GPUs.
Gating network dynamically routes tokens to top-k experts.
Impact: Massive parameter counts with active sparsity; requires expert-parallel routing not simple replication.
Video Visual Recreation (ASCII):
Attention Layer (replicated)
↓
Gating → Top-2 Experts
↓
Expert1 | Expert2 | ... (sharded)
↓
Attention Layer (replicated)
Conclusion: Why Specialized Engines Matter
These 10 optimizations rooted in autoregressive nature, memory explosion, and dynamic workloads explain why LLM inference demands engines like vLLM (paged + continuous batching), SGLang (structured generation), TensorRT-LLM (NVIDIA-optimized kernels), and orchestration layers like Ray.
As models grow and traffic bursts increase, mastering these will separate scalable AI services from toys. The field evolves rapidly speculative decoding, multi-token prediction, and better quantization are next frontiers.
Thanks to Robert Nishihara for the intuitive walkthrough that inspired this deeper dive! If you’re building LLM serving, start with vLLM and scale with Ray.